SchemaSpy is a database schema and data model extraction software. A single java jar schemaspy-6.0.0-rc1.jar which can generate beautiful static html files with graphics and data when pointed to database schemata.
When you download the jar file for schemaspy from http://schemaspy.org all you have to do is run a one line command like below to get a website full of information about your database schema! No kidding. This is how the generated static html website looks like: http://schemaspy.org/sample/index.html
# run on my ubuntu desktop to extract a data model for an oracle schema
$ java -jar /home/kubilay/schemaspy/schemaspy-6.0.0-rc1.jar -t orathin -db your_sid -s your_schema -u your_schema -p your_password -o /home/kubilay/schema/tst/your_output_dir -dp /home/kubilay/drivers/ojdbc7.jar -host your_host -port 1521 -noviews -loglevel finest
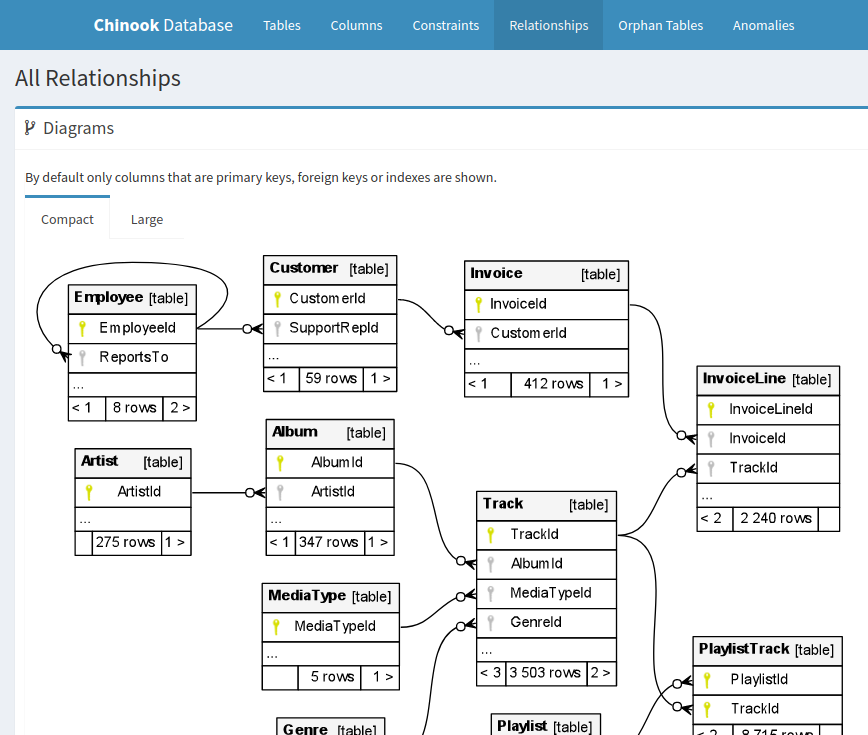
As a result you will get your /home/kubilay/schema/tst/your_output_dir full of static html files and images the jar file will generate using Grapvhiz. Click on index.html and start browsing your database schema. Check out the relationships tab where it has a very nice drawing of your data model. The information schemaspy generates for a database schema is really very rich and so easy to get. A database schema documentation for your database, ready to publish and share.
Well done to John Currier the first developer of this tool now also available on Github. Reading on schemaspy.org, I see that JetBrains recently showed some interest in the tool and is helping with its further development. I just can't praise enough this tool.
Some prerequisites for the tool to run are:
- java 7 or 8 installed https://java.com/en/download/
- You must have graphviz installed http://www.graphviz.org/ (I installed graphviz 2.38.0-1-saucy amd64.deb)
- jdbc drivers (ojcdbc7.jar) installed http://www.oracle.com/technetwork/database/features/jdbc/jdbc-drivers-12c-download-1958347.html (I installed Oracle thin drivers)
Enjoy your data model findings!
